Image Generated Using DALL·E
What Are Supernodes
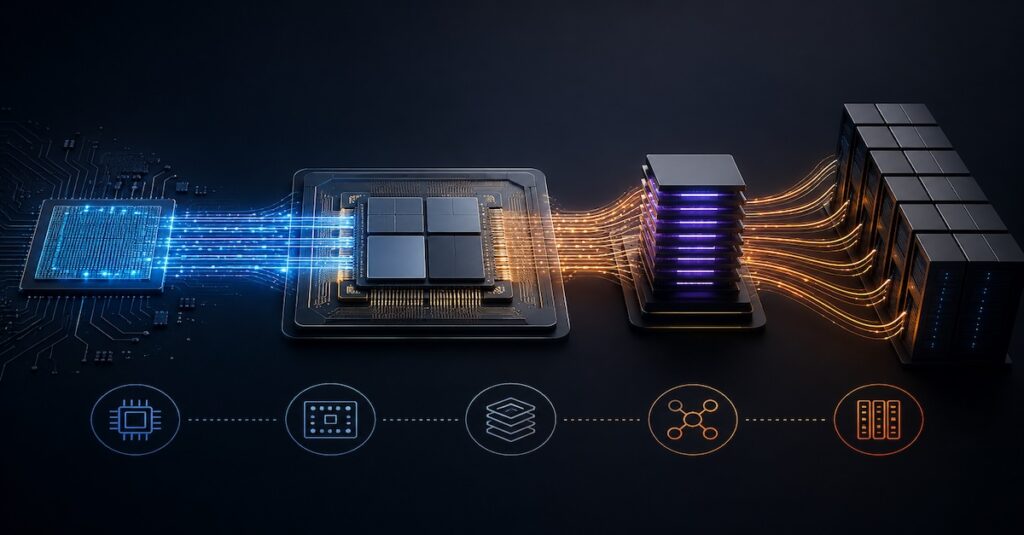
Supernodes are tightly integrated compute domains that combine multiple accelerators into a single, coherent processing unit. Unlike traditional clusters of servers, they operate as one logical system with shared memory, timing, and synchronization. This eliminates the overhead of networking layers, enabling near-instantaneous data movement across all components.
At their core, supernodes rely on specialized interconnect fabrics that provide extremely high bandwidth and low latency between chips. These links allow accelerators to exchange data as if they were on the same die, maintaining coherence and performance even as scale increases. Parallel operations, such as tensor synchronization and gradient updates, occur directly through hardware rather than network protocols.
Supernodes: The Architecture Beyond Servers
Memory and control are also unified. High-bandwidth memory is pooled and accessible to all compute elements, while hardware-level orchestration ensures deterministic synchronization across the domain. This coherence allows workloads to scale efficiently without the communication bottlenecks that limit conventional systems.
Physically, supernodes function as compact, high-density compute islands. They integrate their own power delivery and cooling systems to sustain massive computational loads. Multiple supernodes can be linked together to form large-scale compute facilities, defining a new class of infrastructure built for coherent, high-performance processing at a global scale.
Requirements Of A Supernodes
Creating a supernode requires a complete rethinking of how compute, memory, and communication interact. It is not simply an arrangement of accelerators, but an engineered coherence domain and one that must sustain extreme data movement, deterministic timing, and efficient power conversion within a compact physical footprint.
Every layer of the system, from silicon to cooling, is optimized for tight coupling and minimal latency.
| Requirement Layer | Purpose |
|---|---|
| Semiconductor Packaging | Enable multiple dies to function as a unified compute plane |
| Memory Architecture | Maintain shared, coherent access to large data pools |
| Interconnect Fabric | Provide deterministic, high-throughput communication across accelerators |
| Synchronization & Control | Coordinate compute and data movement with minimal software overhead |
| Power Delivery | Support dense, high-load operation with stability and efficiency |
| Thermal Management | Maintain performance under extreme heat density |
| Reliability & Yield | Preserve coherence across large physical domains |
Meeting these requirements transforms the traditional boundaries of system design. Each component, chip, interposer, board, and enclosure, functions as part of a continuous fabric where data, power, and control are inseparable.
Supernodes thus represent the convergence of semiconductor engineering and system architecture, where every physical and electrical constraint is optimized toward a single goal: sustained coherence at scale.
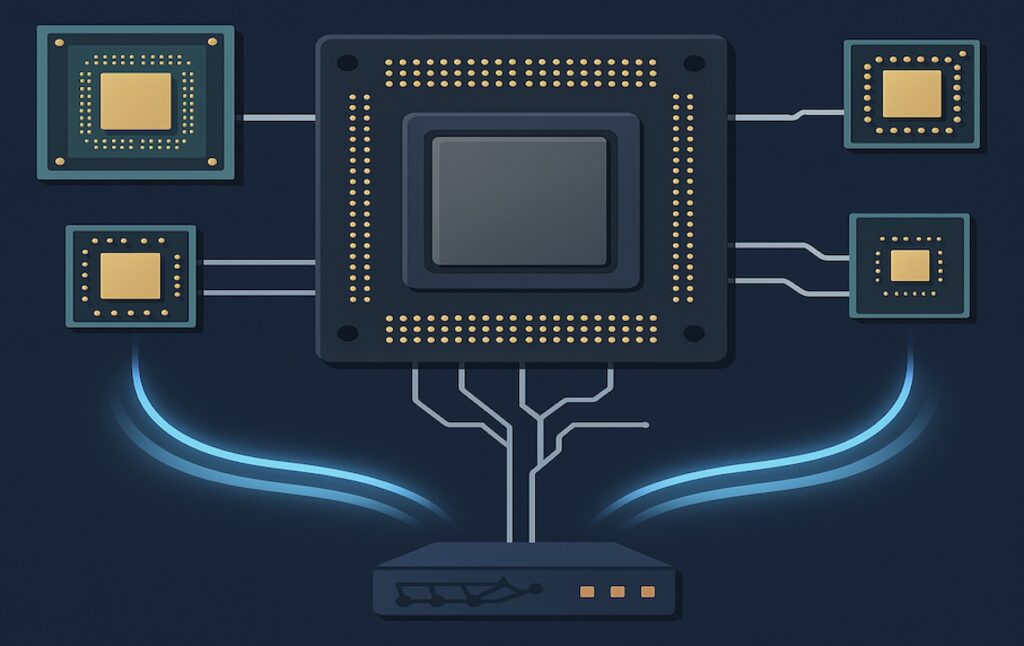
Applications That Benefit From Supernodes Era
Supernodes benefit workloads where communication, not computation, limits performance.
By allowing accelerators to operate as a single, coherent system with shared memory and ultra-fast data exchange, they eliminate the delays that slow down large, synchronized tasks.
The most significant gains are observed in AI training, scientific simulation, and real-time analytics, domains where rapid, repeated data exchange is crucial. Unified fabrics and coherent memory let these workloads scale efficiently, turning communication into a built-in hardware capability rather than a software bottleneck.
Ultimately, supernodes mark a structural shift in computing. As workloads grow more interdependent, progress depends on integration, not expansion.
Why Transition Towards The Supernodes Era
The move toward supernodes stems from the breakdown of traditional scaling methods.
For years, data centers grew by adding more servers, relying on networks to tie them together. This model fails for modern AI and simulation workloads that require constant, high-speed communication between accelerators. Network latency and bandwidth limits now dominate system behavior, leaving much of the available compute underutilized.
Supernodes solve this by bringing computation closer together. Instead of linking separate servers, they combine multiple accelerators into a single, coherent domain connected through high-speed, low-latency fabrics. This eliminates the need for complex synchronization across networks, allowing data to move as if within a single device. The result is higher efficiency, lower latency, and predictable performance even at massive scale.
Energy efficiency further drives the shift. Concentrating computation in coherent domains reduces redundant data transfers and power losses across racks. Localized cooling and power delivery make dense, sustained performance practical.
In essence, the transition toward supernodes is not optional, it is a response to physical and architectural limits. As transistor scaling slows, coherence and integration become the new sources of performance, making supernodes the logical evolution of high-performance computing and AI infrastructure.